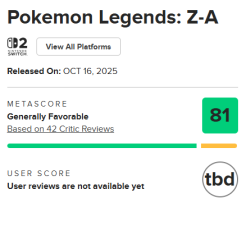
GPT-4.5被評為“類人智能”:圖靈測試中人類辨識率達73%
2025-04-02 15:30:08
人工智能與人類之間的界限,正變得越來越模糊。
近日,加州大學的一個研究團隊公布了一項令人震驚的研究成果:他們對當前最先進的語言模型GPT-4.5進行了圖靈測試,結果顯示,該模型在模擬人類行為方麵表現出驚人的“擬人化”能力。數據顯示,在受試者的判斷中,有多達73%的概率將GPT-4.5誤認為是“真人”,也就是說,在與它對話時,大多數人難以分辨出它其實是一台AI。

圖靈測試再成焦點,GPT-4.5脫穎而出
圖靈測試並非新鮮概念,其最初由英國計算機科學家艾倫·圖靈在1950年的論文《計算機器與智能》中提出,是評估人工智能是否具有人類思維特征的重要方式。如今的標準測試時長一般設定為五分鍾,參與測試的AI需應對由人類測試者提出的一係列問題。如果其回答有30%以上能夠成功“騙過”測試者,使對方誤以為是人類所答,那麼該AI就視為通過測試。
而這次,GPT-4.5不僅輕鬆達標,更將“蒙混過關”的概率提高至73%,這一結果無疑刷新了業內對語言模型智能水平的認知。
與前代相比,擬人化表現躍升明顯
值得一提的是,這項測試結果也為我們提供了對比視角。就在此前的評估中,GPT-4o(GPT-4.5的前一代版本)在圖靈測試中的“人類判斷率”僅為21%。從21%躍升至73%,不僅是一次技術迭代,更體現出GPT-4.5在語言組織、情緒模擬、邏輯推理以及語境適配等多個層麵都更貼近人類思維模式。